19th April, 2024
Availability of the Bhasha SFT Dataset for Supervised Fine-Tuning of Indic Language Models
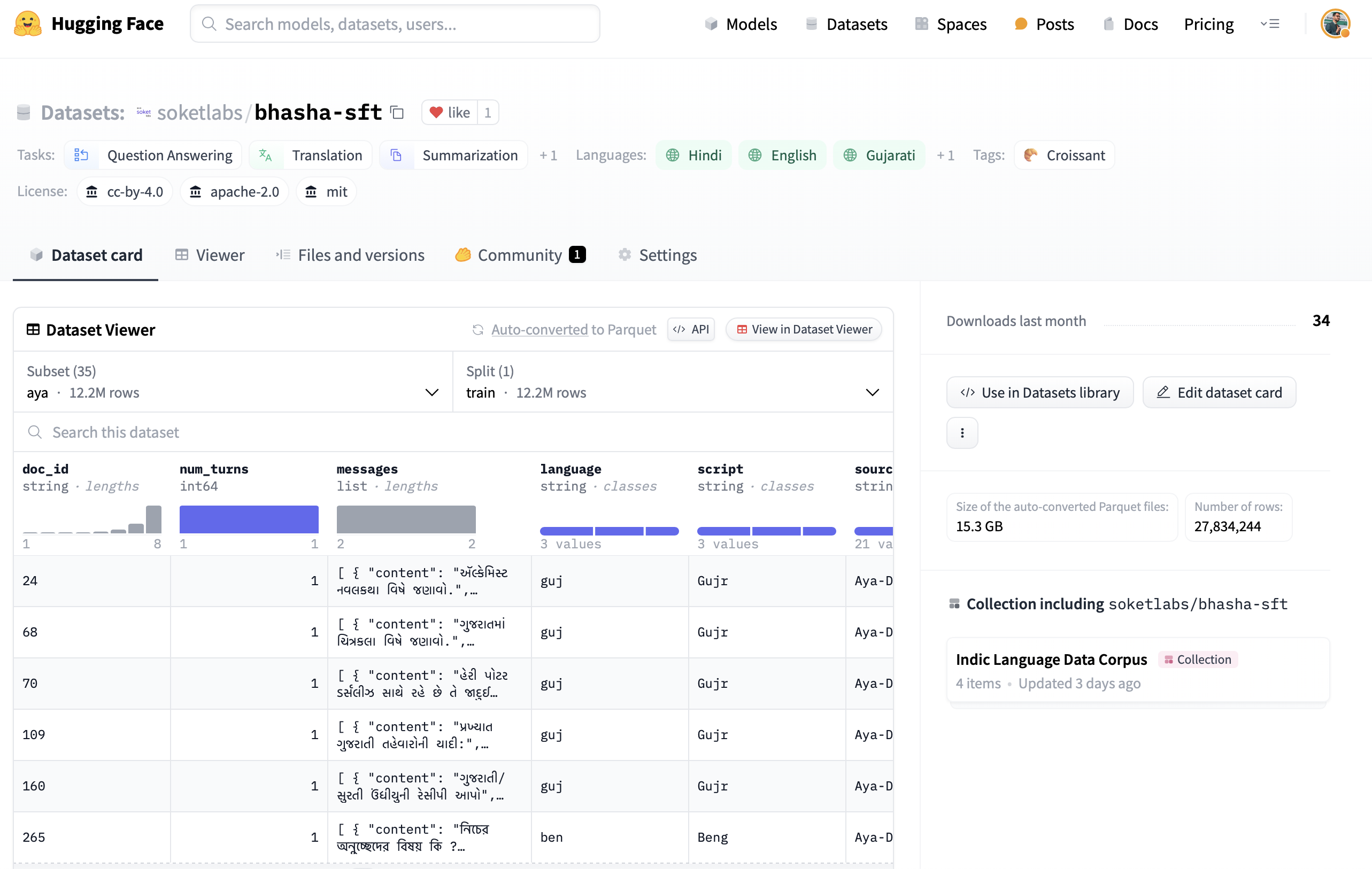
We are pleased to inform the NLP community about the availability of the Bhasha SFT dataset, an extensive collection curated by Soket AI Labs for the supervised fine-tuning of Multilingual Large Language Models (LLMs), focusing on Indic languages. The dataset, compiled from several sources, features over 13 million instruction-response pairs in four languages: Hindi, Gujarati, Bengali, and English. It includes both human-annotated and synthetic data to support a range of complex NLP tasks.
Stay tuned for exciting updates by following us on LinkedIn
Available on Huggingface 🤗: soketlabs/bhasha-sft
Purpose of Bhasha SFT
The Bhasha SFT dataset is designed to aid in the development of language models capable of performing various NLP tasks such as multi-turn conversation, question-answering, text summarization, context-based Q&A, and natural language generation. This dataset provides researchers with the necessary tools to enhance the performance of language models across diverse linguistic settings.
Languages and Licensing
The dataset is available in English, Hindi, Bengali, and Gujarati and is licensed under CC-BY-4.0, Apache-2.0, and MIT, allowing for extensive use, modification, and sharing within the community.
Data Field Descriptions
Each entry in the dataset is meticulously organized with several fields to support a variety of NLP tasks:
- doc_id (str): Identifier for the document.
- num_turns (int): Number of interaction turns for tasks such as dialogues.
- messages (list): A sequence of instructions and responses.
- language (str): Languages used for instructions and responses.
- script (str): Script in which the text is written.
- source (str): The original source dataset.
- task (str): Type of NLP task.
- topic (str): Topic or theme of the content.
Contributing Data Sources
The dataset aggregates contributions from various sources, ensuring a rich and varied compilation:
The availability of the Bhasha SFT dataset is intended to support the ongoing development and refinement of language technologies, particularly in the domain of Indic languages. Curated by Soket AI Labs from multiple sources, this resource is poised to facilitate significant advancements in multilingual NLP research. We invite researchers and developers to utilize this dataset in their work towards innovative solutions and improved language understanding.