30th April, 2024
Introducing Pragna-1B: Soket AI Labs' Multilingual Language Model for Indian Languages
![]()
Available on Huggingface 🤗: soketlabs/pragna-1b
Introduction: Unleashing the Power of Multilingual AI
We at Soket AI Labs are thrilled to unveil India's first open source multilingual model, Pragna-1B available in four Indian languages - Hindi, Gujarati, Bangla and English.
The model is designed to cater to the rich tapestry of Indian languages, significantly expanding the horizons of AI inclusivity and accessibility. As we step into an era where technology transcends linguistic boundaries, Pragna-1B emerges as a beacon of innovation, ready to bridge language barriers and enhance user engagement across diverse linguistic landscapes.
Highlights of Pragna-1B:
- Architecture: Pragna-1B features a Transformer Decoder-only model with 1.25 billion parameters, with a context length of 2048 tokens.
- Designed for Edge AI: Engineered to deliver state-of-the-art performance for vernacular languages in the smallest form factor, ideal for deployment on-device.
- Small Language Model (SLM) with Robust Capabilities: Even with 1.25 parameters, Pragna-1B’s performance is comparable to larger 7 billion parameter sized models, offering comprehensive multilingual support for English, Hindi, Bangla, and Gujarati.
- Culturally Contextualised Training: The model has been meticulously trained on curated datasets specifically designed to encompass the Indian context, ensuring accurate and culturally relevant outputs.
- Ethical and Responsible AI: Committed to upholding human values, the model is aligned to generate ethical responses.
- Open Source Availability: The base version of Pragna-1B is accessible as an open-source model on Hugging Face, facilitating development and collaboration within the community.
Architecture Overview
Pragna-1B is a decoder-only transformer model inspired by TinyLlama, featuring the following specifications:
- Layers: 22
- Attention Heads: 32
- Context Length: 2048
- Hidden Dimension: 2048
- Expansion Dimension: 5632
- Vocabulary Size: 69632
This model incorporates Rotary Positional Encoding to infuse positional information into the embeddings, utilising a base of 10,000. It employs RSNorm with an epsilon value of 1e-5 and the Sigmoid Activation Unit (SiLU) as the activation function. Additionally, Pragna-1B adopts Grouped Query Attention, an alternative to Multi-Head Attention, which enhances training and inference speed while reducing memory bandwidth. This also supports the use of lower-compute devices for inference tasks.
Pragna-1B is trained on our proprietary platform, GenAI Studio, a modular AI Developer Platform designed to support any GenAI model architecture. It is capable of scaling across thousands of GPUs or accelerators and is built to be fault-tolerant. The development of this model leveraged Triton, an open-source language from OpenAI, for crafting high-performance custom fused CUDA Kernels for various operations. Furthermore, the model uses Fully Sharded Data Parallel (FSDP) for distributed and parallel training and incorporates the state-of-the-art FlashAttention2 to accelerate training and inference.
Developing an Efficient Tokenizer for Indian Languages
Pragna employs a Byte-Pair Encoding (BPE) tokenizer, specifically trained for handling Indian languages. The tokenizer was trained on six Indian languages—Hindi, Bangla, Urdu, Tamil, Kannada, and Gujarati—before combining them into a unified tokenizer. This unification was achieved through a union set operation, which ensures each language is represented equitably. The merging rules were selected to optimise compression of text into tokens, effectively making the vocabulary size 69,632.
The tokenizer demonstrates its efficiency through its fertility score, a metric that measures the average number of tokens produced per word. This score is crucial as it reflects the tokenizer's ability to compress text into tokens—computer representable integers—with a lower score indicating more efficient tokenization. Notably, our tokenizer not only performs comparably to those designed for English but excels in processing Hindi, Bangla, Gujarati, Tamil, Kannada, and Urdu as shown in the graph below. For example, the Gemma-7b model produces 5.8 tokens per word whereas Pragna-1b generates 2.8 tokens per word for Kannada almost doubling the throughput just with tokenization.
Moreover, our tokenizer addresses a significant issue prevalent in existing models: the inadequate representation of Indic languages. Traditional models often dissect Indic characters into bytes, severely hindering performance and requiring an excessive number of tokens for effective training. In contrast, our approach significantly enhances model efficiency and performance across Indian languages.
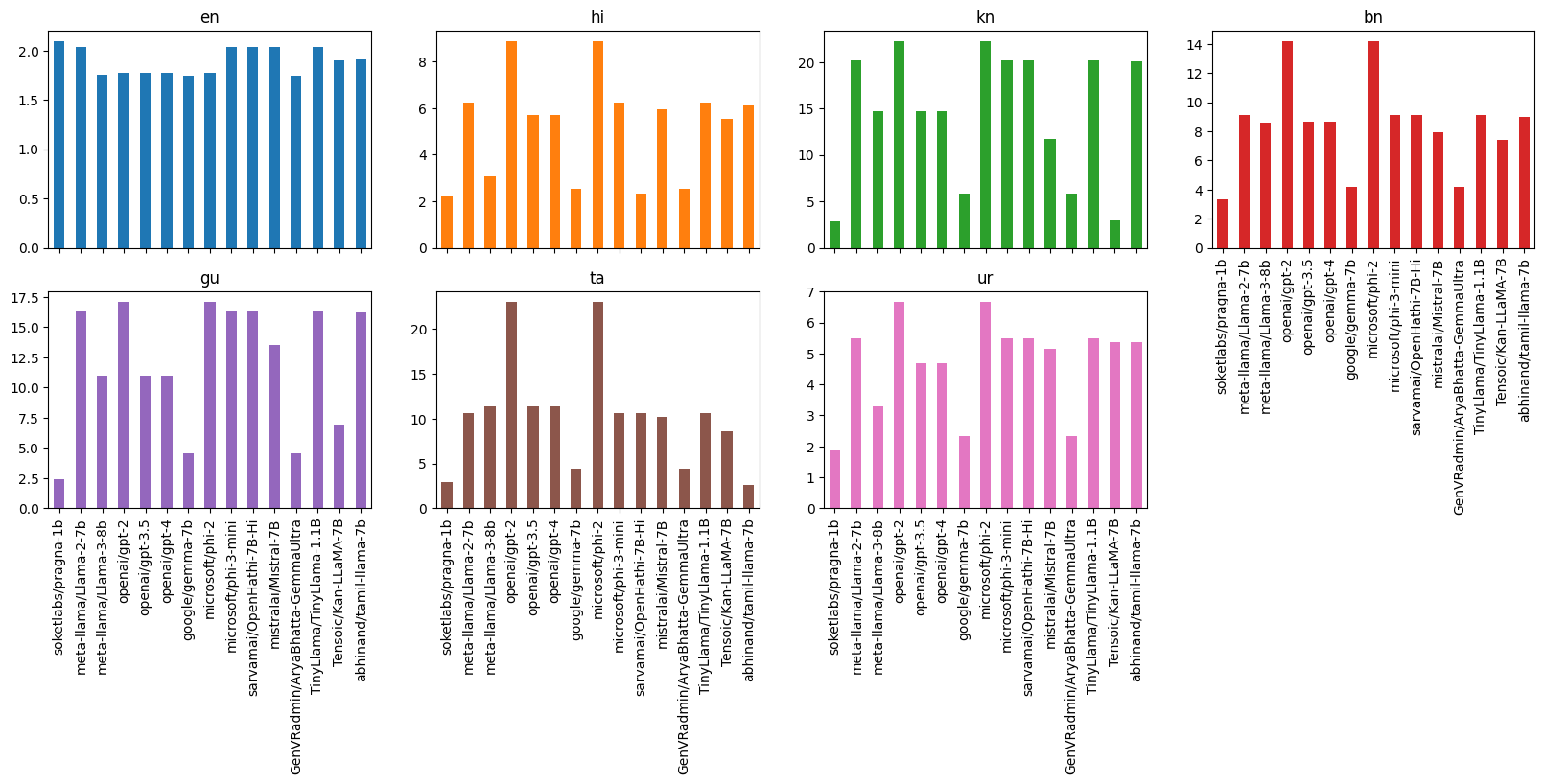
Graph above shows the fertility score for six Indian languages when tokenized using various LLMs.
| en | hi | kn | bn | gu | ta | ur | |
|---|---|---|---|---|---|---|---|
| soketlabs/pragna-1b | 2.1 | 2.26 | 2.85 | 3.3 | 2.41 | 2.94 | 1.87 |
| meta-llama/Llama-2-7b | 2.03 | 6.24 | 20.22 | 9.12 | 16.36 | 10.66 | 5.49 |
| meta-llama/Llama-3-8b | 1.76 | 3.07 | 14.68 | 8.6 | 10.96 | 11.4 | 3.3 |
| openai/gpt-2 | 1.78 | 8.89 | 22.28 | 14.2 | 17.12 | 23.08 | 6.68 |
| openai/gpt-3.5 | 1.78 | 5.73 | 14.68 | 8.68 | 10.96 | 11.41 | 4.68 |
| openai/gpt-4 | 1.78 | 5.73 | 14.68 | 8.68 | 10.96 | 11.41 | 4.68 |
| google/gemma-7b | 1.74 | 2.52 | 5.81 | 4.2 | 4.57 | 4.39 | 2.34 |
| microsoft/phi-2 | 1.78 | 8.89 | 22.28 | 14.2 | 17.12 | 23.08 | 6.68 |
| microsoft/phi-3-mini | 2.03 | 6.24 | 20.22 | 9.12 | 16.36 | 10.66 | 5.49 |
| sarvamai/OpenHathi-7B-Hi | 2.03 | 2.35 | 20.22 | 9.12 | 16.36 | 10.66 | 5.48 |
| mistralai/Mistral-7B | 2.04 | 5.97 | 11.72 | 7.93 | 13.5 | 10.15 | 5.15 |
| GenVRadmin/AryaBhatta-GemmaUltra | 1.74 | 2.52 | 5.81 | 4.2 | 4.57 | 4.39 | 2.34 |
| TinyLlama/TinyLlama-1.1B | 2.03 | 6.24 | 20.22 | 9.12 | 16.36 | 10.66 | 5.49 |
| Tensoic/Kan-LLaMA-7B | 1.9 | 5.56 | 2.94 | 7.38 | 6.95 | 8.59 | 5.37 |
| abhinand/tamil-llama-7b | 1.91 | 6.14 | 20.07 | 8.99 | 16.23 | 2.55 | 5.38 |
Training Data
The quality and quantity of training data are crucial in imparting linguistic and semantic understanding into any language model. One significant challenge in developing language models for Indian languages is the scarcity of large-scale corpora. With all 22 scheduled Indian languages representing less than 1% of internet-scale datasets like mC4, we were compelled to create "Bhasha," a series of high-quality datasets designed for pretraining and instruction fine-tuning of Indian models.
Bhasha-wiki: Starting with 6.3 million English Wikipedia articles, we translated these into six Indian languages to create a dataset of 44.1 million articles. With over 45.1 billion Indic tokens, Bhasha-wiki serves as a foundational resource for linguistic and AI research. It supports a broad spectrum of applications, including machine translation, natural language processing, and language model training.
Bhasha-wiki-indic: A refined subset of the Bhasha-wiki, Bhasha-wiki-indic is curated to enrich models with an in-depth understanding of the Indian context. This subset specifically includes content of significant relevance to India, aiming to develop culturally resonant AI applications.
Bhasha-SFT: Designed to facilitate the development of language models capable of handling various NLP tasks such as multi-turn conversation, question-answering, text summarization, context-based Q&A, and natural language generation, the Bhasha-SFT dataset provides essential tools for enhancing language model performance across diverse linguistic landscapes.
We have also incorporated external datasets like SlimPajama, a clean and deduplicated dataset by Cerebras featuring 627 billion tokens with a majority in English, and Sangraha-Verified by AI4Bharat, a 15 million tuple dataset in multiple Indian languages, curated from human-verified sources.
Training
Model Weight Initialization: Instead of starting from a random distribution, we initialise the weights using TinyLlama-1.1B-Chat-v1.0, a model under the Apache-2.0 licence. This approach leverages the foundational knowledge of an existing model, reducing costs and facilitating the transfer learning from the English domain to the Indian language domain.
Indic Tokenizer: Our base tokenizer, borrowed from Llama-2, initially had a vocabulary size of 32,000. To this, we added new tokens for six Indian languages, expanding the vocabulary to 69,632. This enhancement significantly improved the fertility score across all six languages.
Embedding Initialization for New Tokens: Drawing inspiration from John Hewitt’s research, "Initializing New Word Embeddings for Pretrained Language Models", we opted for a targeted approach to initialising embeddings for new tokens. Instead of averaging all existing embeddings with added noise, we used a subset of relevant embeddings. This method assumes each new Indic token can be tokenized using Llama-2's existing vocabulary. By averaging these related embedding vectors, we achieved a more accurate representation with lower KL-divergence. We are preparing a detailed blog post to share our methodology and findings on efficient vocabulary expansion.
Embedding Alignment: Initially, we aligned only the embedding and lm_head, keeping other tensors frozen. We utilised a parallel sentences dataset from Bhasha-wiki, pairing sentences in one of the six Indian languages with their English counterparts. Loss was computed solely on the English sentences, aiding in the alignment of model embeddings and facilitating the generation of coherent though nonsensical text in all six languages with minimal training.
Continual Pretraining: We subsequently enabled all 1.25 billion parameters for further training, focusing on three languages—Hindi, Bangla, and Gujarati—due to compute limitations. We maintained high, equal sampling probabilities for these languages while incorporating data from SlimPajama, predominantly in English. The model processed approximately 150 billion tokens (3.15 trillion considering the base model) over about 8,000 GPU-hours. Training specifics included 3,000 hours on 4xA100-40 GiB and 5,000 hours on 8xA100-80 GiB systems.
Training Parameters:
- Precision: BFloat16
- Batch Size: 2k - 2.5k
- Context Length: 2,048
- Learning Rate: 3e-5
- Optimizer: AdamW
- LR Scheduler: Cosine
- Mixed Precision Training
Instruction Fine-Tuning: The model is undergoing supervised fine-tuning across multiple tasks, including conversation, question-answering, summarization, and paraphrasing using Bhasha-SFT which comprises over 13 million instances of instruction-response data in three Indian languages from Aya Collection, Indic-align, and Samvaad.
Ethics and Safety Alignment: Safety and ethics alignment is an important part of the supervised fine–tuning step. To make sure Pragna is aligned to human values, we have been working on building our own datasets specifically curated to prevent the model from generating unethical or potentially harmful content. This data is being exposed to the model during SFT.
Ongoing Developments and Community Engagement: As the model is currently undergoing further instruction tuning and safety alignment, we plan to release pragna-1b-it model weights to the community under an open-source licence soon. An initial research preview of the instruction-tuned model is available via a chat interface, though it is not recommended for production use due to its tendency to generate convincing yet factually incorrect information. We eagerly anticipate feedback from the community to further refine and enhance our models.
Inference
Next Token Prediction
| Context | Tokens Predicted |
|---|---|
| India is one of the most | India is one of the most exciting places to travel to in Asia. The country hosts a wide variety of cultures and offers a plethora of attractions across the country. There's a lot you can do here and the tourists are always on the lookout for the new things to do and see. If you're looking to travel to India for your next adventure, you'll be pleased to know that you can find a ton of things to do in the country. From the temples to the beaches, there's a lot you can see and do here. One of the best things for visitors to do in India is to visit Jaipur. The capital city of Rajputana, Jaipur is a beautiful city that's known as the "City of Lives". |
| नरेंद्र मोदी का जन्म | नरेंद्र मोदी का जन्मदिन आज मनाया जा रहा है। इस मौके पर प्रधानमंत्री नरेंद्र मोदी ने ट्वीट कर लिखा कि 'आज देश को एक नया संसद भवन मिला है, जिसे आप लोगों ने बधाई दी है। भारत और भारतवासियों को यह संसद बहुत ही महत्त्वपूर्ण है और इसका उपयोग देश के विकास में बहुत अधिक योगदान देगा। आज हमारे देश में एक संसद बनी हुई है जो हमारे देश की लोकतांत्रिक प्रक्रियाओं को मजबूत बनाती है। |
| Prime minister Modi | Prime minister Modi's visit to China: PM Modi is scheduled to arrive in Beijing on Thursday. PM Narendra Modi will be the first Indian prime minister to visit China since former President Mao Zedong, who visited India in 1959 and was assassinated by Chinese soldiers a year later. The two leaders are expected to discuss regional security issues such as terrorism, trade and energy cooperation during their talks. |
| महात्मा गांधी | महात्मा गांधी एक स्वतंत्र व्यक्ति, एक आत्मनिर्भर और एक अत्यंत लोकप्रिय नेता थे। उन्होंने अपने जीवनकाल में देश को एक नई दिशा देने के लिए बहुत कुछ किया। समाज के विभिन्न क्षेत्रों में उनके योगदान के लिए उन्हें सम्मानित किया गया था। |
| ब्रिटिश राजशाही | ब्रिटिश राजशाही के विघटन के बाद, इंग्लैंड और वेल्स में ब्रिटेन की संसद का गठन हुआ। संसद ने 1807 में अपने पहले अधिनियम, "द क्राउन की विधेयक" (एक्ट ऑफ द डेमोक्रैटिक) को मंजूरी दी, जिसमें प्रत्येक राज्य से एक निर्वाचित सदस्य चुना गया। |
| মহাত্মা গান্ধী | মহাত্মা গান্ধী ছিলেন আন্তর্জাতিক সমাজতান্ত্রিক আন্দোলনের অন্যতম প্রধান নেতা। তিনি ভারতের স্বাধীনতা সংগ্রামে তাঁর ভূমিকা অপরিসীম। ১৯৪৭ সালের ১৫ আগস্ট ভারতে বিপ্লব ঘটে। ১৯৪৮ সালে মহাত্মা গান্ধীর মৃত্যু হয়। |
| ভারতের স্বাধীনতা দিবসে | ভারতের স্বাধীনতা দিবসে (১৫ আগস্ট) সকাল থেকেই আলোচনা চলছে দেশজুড়ে। সেইসঙ্গে সামাজিক যোগাযোগ মাধ্যমেও ভাইরাল হয়েছে ভারতীয় নাগরিকদের একটি ছবি যা দেখলে মনে হবে একজন বিপ্লবী। |
| ભારતમાં સ્વતંત્રતા દિવસ | ભારતમાં સ્વતંત્રતા દિવસ પર દેશભરમાં વિવિધ કાર્યક્રમો યોજાયા હતા. આ દરમિયાન ઘણા લોકો પોતાના પરિવાર સાથે એકસાથે જોવા મળ્યા હતા. દેશના વડાપ્રધાન નરેન્દ્ર મોદીએ ભારતના સ્વાતંત્ર્ય દિવસ પર પોતાના ઘરે એક ખાસ વીડિયો શેર કર્યો છે. |
| ક વખતે | ક વખતે, તેમણે તેમના મિત્ર અને સહાયક વિલિયમ હેનરી મેકડોનાલ્ડ સાથે મળીને "ધ ઓરિજિનલ મેન ઓફ ધ ડેડ" નામના પુસ્તકનું નિર્માણ કર્યું હતું; તે 1961માં પ્રકાશિત થયું હતું. 1958માં, તેમણે ધ ન્યૂ યોર્કર માટે લેખક અને સંપાદક પિતા તરીકે કામ કર્યું હતું. |
| એક સમયે એક રાજા જંગલમાં રહેતો હતો. તેમણે | એક સમયે એક રાજા જંગલમાં રહેતો હતો. તેમણે, એક દિવસ રાજાને કહ્યું, "હું તમને મારી જાતને એક સ્ત્રી તરીકે આપું છું." રાજા ખુશ થયો. તેમણે તેને તેના ઘરમાં લઈ ગયા. તે દિવસે રાણી પોતાના પતિ સાથે ઘરે આવી અને કહ્યું કે તે તેની પાસે છે. રાજાએ તેને પૂછ્યું કે શું તેણે તેની સાથે લગ્ન કર્યા છે ? રાજા અને રાણીએ પૂછ્યું - હા. ત્યારે તેમણે કહ્યું કે, "તમે મને તમારી સાથે લગ્ન કરવાનું વચન આપ્યું છે. હવે મારે તમારા પર વિશ્વાસ રાખવો જોઈએ નહીં". |
SFT outputs
| Instruction | Response |
|---|---|
| Tell me about India | India is a vast and diverse country located in South Asia. It is the seventh-largest country in the world by land area and is also the most populous country, with over 1.4 billion people as of my last update. Here are some key points about India: Inchurching History: Modern India has a long and rich history that spans thousands of years. It was under various empires for many centuries before it became part of the British Empire in the 18th century. The Indian Rebellion of 1857 was a significant event that led to the independence of India from British rule and its unification into one nation. Economy: India's economy is one of the largest in the world, with economic growth reportedly averaging around 7% per year since 1990. It is considered one of the most advanced economies in the world and hosts several multinational companies, including Tata Motors, Airtel, HCL Teletracns, and Infosys among others. Society: India's society is diverse and pluralistic, with individuals belonging to different religions, ethnicies, and social classes. It faces challenges such as poverty, inequality, and environmental degradation. |
| मुझे भारत के बारे में बताओ? | भारत दक्षिण एशिया में स्थित एक विशाल और वैश्विक देश है। यह भूमि क्षेत्र के हिसाब से दुनिया का सातवां सबसे बड़ा देश है और सबसे अधिक आबादी वाला देश है, जहां मेरी पिछली अद्यतन जानकारी के अनुसार 12.2 करोड़ लोग हैं। वे हिंदू समुदाय का नेतृत्व करते हैं, और एक संघीय संसदीय लोकतांत्रिक गणराज्य है। |
| भारत के प्रधान मंत्री कौन हैं | नरेंद्र मोदी भारत के वर्तमान प्रधानमंत्री हैं। |
| भारत को आजादी कब मिली | 1942 में भारत के स्वतंत्रता संग्राम के दौरान भारत ने अपनी सार्वजनिक रूप से घोषित स्वतंत्रता के लिए लड़ाई लड़ी थी। यह युद्ध 1947 तक चला, तब भारत की स्थापना हुई और इसे भारतीय संविधान द्वारा मान्यता प्राप्त हुई। |
| আমাকে ভারত সম্পর্কে বলুন | ভারত একটি বিশাল এবং বৈচিত্র্যময় দেশ যা বৈচিত্র্যময় সাংস্কৃতিক ও ধর্মীয় দৃষ্টিভঙ্গি প্রদান করে। এটি বিভিন্ন ভাষার কেন্দ্রীভূত কাঠামো এবং বিভিন্ন ধর্মীয় পদ্ধতির জন্য পরিচিত। |
| বৈজ্ঞানিক অর্জন মানে কি? | বৈজ্ঞানিক অর্জনগুলি গণনা, যোগাযোগ এবং বৈজ্ঞানিক সংস্থার মাধ্যমে বা ব্যক্তিগতভাবে অর্জিত বিভিন্ন অর্জন হতে পারে। |
| ભારતની રાજધાની શું છે? | દિલ્હીનું રાજધાની સ્થાન છે. |
| મને ભારત વિશે કહો | ભારત એક વિશાળ અને વૈવિધ્યસભર દેશ છે જે વિવિધ રાજકીય પ્રદેશો અને વ્યવસાયિક વિભાગો છે. તે દક્ષિણ એશિયામાં આવેલો છે અને માનવતાવાદી અને આર્થિક બાબતોમાં સક્રિય રીતે ભાગ લે છે. |
| દિલ્હી ક્યાં છે અને તે શેના માટે પ્રખ્યાત છે? | દિલ્હીનું સ્થાન ભારતના દિલ્હીમાં છે. તે તેની સાંસ્કૃતિક અને ઐતિહાસિક મહત્વ માટે જાણીતું છે. |
| কলকাতার ঐতিহাসিক তাৎপর্য কী। বিস্তারিত বলুন। | কলকাতা, ভারতের একটি ঐতিহাসিক শহর। এটি ভারতীয় উপমহাদেশের বৃহত্তম শহরগুলির মধ্যে একটি। শহরের অভ্যন্তরীণ অঞ্চলে বিভিন্ন প্রাকৃতিক দৃশ্য এবং প্রাসাদ রয়েছে যা এটিকে বিশ্বের সেরা শহর করে তুলেছে। এই শহরে বেশ কয়েকটি প্রাচীন এবং মধ্যযুগীয় স্থাপত্যের উদাহরণ রয়েছে এবং এখানে অনেক বৈচিত্র্যময় জীবনযাত্রা রয়েছে। |
Research Preview: spaces/pragna-chat
Disclaimer: An initial checkpoint of the instruction tuned model is made available as a research preview. It is hereby cautioned that the model has the potential to produce hallucinatory and plausible yet inaccurate statements. Users are advised to exercise discretion when utilizing the generated content.
Performance and Benchmarking
Hindi
| Arc-Easy | Arc-Challenge | Hellaswag | Average | |
|---|---|---|---|---|
| pragna-1b | 0.33 | 0.22 | 0.35 | 0.30 |
| sarvamai/OpenHathi-7B-Hi-v0.1-Base | 0.3582 | 0.2645 | 0.4315 | 0.35 |
| meta-llama/Llama-2-7b-hf | 0.295 | 0.2406 | 0.3789 | 0.30 |
| google/gemma-7b | 0.5926 | 0.4258 | 0.6341 | 0.55 |
| meta-llama/Meta-Llama-3-8B | 0.5354 | 0.3541 | 0.6072 | 0.50 |
Gujarati
| Arc-Easy | Arc-Challenge | Hellaswag | Average | |
|---|---|---|---|---|
| pragna-1b | 0.32 | 0.22 | 0.37 | 0.30 |
| google/gemma-7b | 0.4954 | 0.3208 | 0.5673 | 0.46 |
English
| Arc | Hellaswag | MMLU | TruthfulQA | Winogrande | GSM8K | Average | |
|---|---|---|---|---|---|---|---|
| pragna-1b | 0.3 | 0.51 | 0.27 | 0.38 | 0.56 | 0 | 0.34 |
| TinyLlama/TinyLlama-1.1B-Chat-v1.0 | 0.36 | 0.61 | 0.25 | 0.37 | 0.61 | 0.02 | 0.37 |
| meta-llama/Meta-Llama-3-8B-Instruct | 0.6 | 0.82 | 0.67 | 0.51 | 0.77 | 0.68 | 0.66 |
| meta-llama/Llama-2-7b-hf | 0.53 | 0.78 | 0.46 | 0.39 | 0.74 | 0.14 | 0.51 |
Eval numbers for Hindi and Gujarati are taken from Indic LLM Leaderboard and English from HF's Open LLM Leaderboard. We are running benchmarks for Bangla and will be updated soon.
Pragna-1b, boasting 1.25 billion parameters, demonstrates performance akin to that of more expansive models such as OpenHathi-7b and Llama-2-7b, and falls within a comparable range with gemma-7b. However, there is a trade-off in English language proficiency when compared to the base model, TinyLlama. This difference arises from the model's integration of extensive information from three Indian languages into the same parameter space. Essentially, Pragna-1b manages to encapsulate a vast corpus of global knowledge, totaling close to 1 TiB, within a remarkably constrained latent space of just 2.3 GiB (BFloat16).
These are preliminary benchmarking results for Pragna-1B. However, for Indian language benchmarking, we have to be careful in interpreting these figures, as the quality of benchmarking data is currently suboptimal. This limitation largely stems from the reliance on datasets generated through machine translations. We are working to develop comprehensive benchmarks that assess both the linguistic understanding and contextual intelligence of large language models across a variety of fields and tasks for all Indian languages.
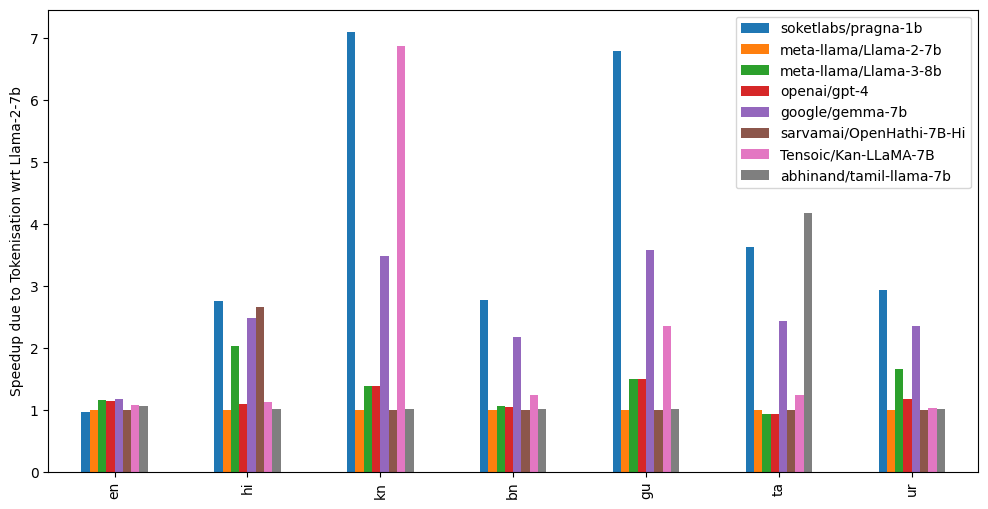
Pragna-1B achieves substantial speed enhancements, demonstrating approximately 3x, 7x, 3x, and 6.5x acceleration for Hindi, Kannada, Bangla, and Gujarati, respectively, relative to Llama-2-7B when considering efficient tokenization alone. The actual throughput and speed improvements are expected to be even greater, owing to reduced computational demands facilitated by a parameter count nearly 7 times lower than that of Llama-2-7B.
Future Work
Alignment for Factual Accuracy: While the model demonstrates good linguistic understanding, it is imperative to align it more closely with factual veracity. Addressing instances of factual hallucination remains a top priority, as we strive to ensure that the model consistently delivers accurate and reliable information.
Expansion of Linguistic Scope: In our pursuit of linguistic inclusivity, we aim to broaden the knowledge base of the model by incorporating additional Indian languages. This expansion involves not only introducing more linguistic tokens but also deepening the model's understanding of the nuances inherent in diverse language structures.
Mixture of Experts for Multilingual Proficiency: To facilitate seamless communication across a spectrum of languages, we are exploring the implementation of a Mixture of Experts approach. This will enable the model to adeptly correlate complexities of multilingual interactions, thereby enriching its linguistic capabilities.
Architectural Innovation and Experimentation: Being a research first team, we will strategise researching and experimenting with novel architectures to innovative solutions and optimise the model's performance across various domains and use cases.
Decoupling Knowledge and Language Understanding: A key focus of our future endeavours involves refining the model's architecture to effectively separate knowledge acquisition from language understanding. By delineating these two components within the model's architecture, we aim to bolster its capacity for multilingual knowledge transfer.
Distillation and Quantization for Efficiency: Focussing on the importance of efficiency without compromising performance, we will be developing distilled and quantized versions of the model. These streamlined iterations harness the power of compression techniques to maximise computational efficiency while upholding the model's performance.
Conclusion
Pragna-1B's introduction holds significant promise for India, promising to revolutionize sectors like education, governance, and commerce. By supporting Indian languages, it fosters inclusivity, expands access to information, and empowers communities in the digital economy. As it evolves, Pragna-1B can bridge linguistic divides, foster cross-cultural understanding, and drive socioeconomic development, making a lasting impact on India's digital landscape.