17th April, 2024
Introducing the "Bhasha" Series 🚀: Advancements in Indic Language AI Datasets
Soket Labs is pleased to announce 🥳 the release of the "Bhasha" series, commencing with two significant datasets: "bhasha-wiki" and "bhasha-wiki-indic". These datasets are engineered to support the development of AI models that are attuned to the linguistic and cultural nuances of India 🫡, representing a crucial step forward in the diversification of linguistic resources in computational linguistics. By making these datasets available in an open-source format, we aim to foster a collaborative environment where developers and researchers across India can contribute to and benefit from inclusive and contextually aware AI technologies
Stay tuned for exciting updates by following us on LinkedIn
Bhasha-wiki: A Comprehensive Corpus for Indic Language Research
Available on Huggingface 🤗: soketlabs/bhasha-wiki
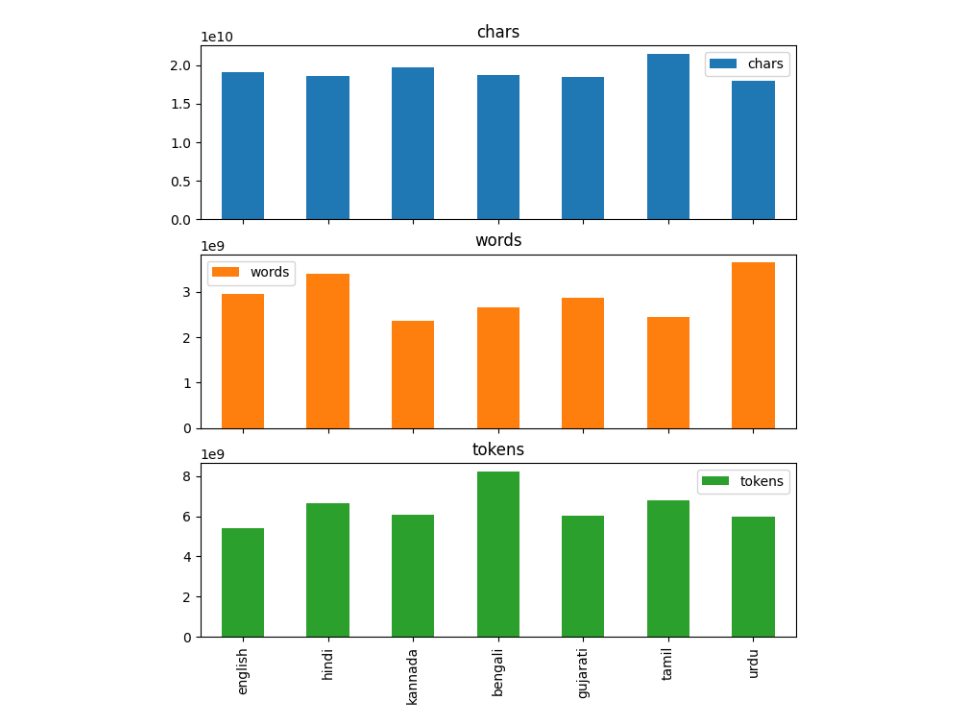
The "bhasha-wiki" dataset presents a comprehensive corpus consisting of 44.1 million Wikipedia articles translated into six major Indian languages from 6.3 million English articles. This corpus, encompassing over 45.1 billion Indic tokens, serves as a foundational resource for linguistic and AI research, facilitating a wide range of studies into machine translation, natural language processing, and language model training.
Dataset Characteristics:
- Extensive Lexical Volume: The corpus is substantial, with a total size of 117 GiB, containing 44,418,479 rows and over 20 billion words.
- Linguistic Diversity: This dataset supports a multilingual framework, including Hindi, Gujarati, Urdu, Tamil, Kannada, Bengali, and English, crucial for cross-linguistic studies.
- Translation Methodologies: Utilising IndicTrans2, powered by a significant computational resources (3360 GPU-hours on AWS), each article was translated with high fidelity to the original content. Segmentation and translation were handled sentence-by-sentence, with adaptations made for longer sentences to maintain semantic integrity.
| Sentences | Characters | Words | Tokens | Rows | |
|---|---|---|---|---|---|
| english | 149,636,946 | 19,009,297,439 | 2,954,105,643 | 5,430,358,976 | 6,345,497 |
| hindi | 149,636,946 | 18,622,892,252 | 3,382,736,074 | 6,635,241,630 | 6,345,497 |
| kannada | 149,636,946 | 19,679,016,421 | 2,349,908,384 | 6,083,839,825 | 6,345,497 |
| bengali | 149,636,946 | 18,741,174,694 | 2,663,832,869 | 8,248,287,687 | 6,345,497 |
| gujarati | 149,636,946 | 18,453,210,446 | 2,867,239,209 | 6,032,149,490 | 6,345,497 |
| tamil | 149,636,946 | 21,457,803,696 | 2,441,061,609 | 6,777,927,96 | 6,345,497 |
| urdu | 149,636,946 | 17,921,351,051 | 3,641,717,085 | 5,966,954,204 | 6,345,497 |
| - | ----------- | ------------ | ------- | -------- | ------ |
| Total | 1,04,74,58,622 | 133,884,745,999 | 20,300,600,873 | 45,174,759,774 | 44,418,479 |
Note: Tokens are calculated using pragna-1b tokenizer
Characters, words and token distribution for each language is shown in the image.
Bhasha-wiki-indic: Tailored Dataset for Enhanced Indian Contextual Relevance
Available on Huggingface: soketlabs/bhasha-wiki-indic
The "bhasha-wiki-indic" dataset, a refined subset of the "bhasha-wiki", is specifically curated to enrich models with a deeper understanding of the Indian context. This subset was meticulously selected to include content with significant relevance to India, enhancing the potential for developing culturally resonant AI applications.
Methodology:
- Focused Semantic Filtering: Initial filtering employed keyword detection ('india' or 'indian'), refined by a topic classifier, achieving an 84% accuracy in distinguishing relevant content.
- Content Extraction and Processing: Approximately 208,000 articles were identified as contextually relevant and subsequently extracted for six Indian languages, preparing this dataset as a specialised tool for AI models requiring deep cultural comprehension.
Dataset Specifications:
- Content Volume: The dataset comprises 200,820 rows with nearly 1.54 billion tokens distributed among several languages, providing a rich linguistic base for detailed computational analysis.
Contributions to the Field and Future Directions
These datasets are expected to significantly impact research in computational linguistics and AI by providing high-quality, large-scale resources for training models that require a nuanced understanding of Indian languages and contexts. They also serve as a platform for further scholarly inquiry into algorithmic translations and cultural specificity in AI technologies.
Open Access and Collaborative Engagement
Released under the CC-by-SA-3.0 licence, these datasets facilitate both academic and commercial use, promoting a wide dissemination and application in diverse settings. We invite the global research community to engage with these resources, further enriching the datasets and exploring new frontiers in AI research.
As we continue to develop the "Bhasha" series, we remain committed to advancing the state of AI with a focus on ethical considerations and inclusivity in technology.
About Soket Labs:
Soket Labs, a visionary AI research firm, is at the forefront of promoting advancements towards ethical Artificial General Intelligence (AGI). Our mission is to foster a form of general intelligence that excels in efficiency and accessibility, thereby democratising cutting-edge technology for diverse applications, including autonomous robots, edge devices, and large clusters.