12th November, 2025
Building CoSHE-Eval: A Code-Switching ASR Benchmark for Hindi–English Speech
The dataset is publicly available on 🤗: soketlabs/CoSHE-Eval
Introduction and Motivation
Automatic Speech Recognition (ASR) research in India has evolved rapidly, yet the majority of existing benchmarks remain monolingual. For instance, datasets such as Vistaar focus exclusively on Hindi (Devanagari script), providing limited insight into multilingual and mixed-language speech performance.
However, real-world Indian conversations are rarely monolingual. Code-switching—alternating between two or more languages within a single utterance—is a natural linguistic behaviour across India. In particular, Hindi–English mixing (Hinglish) is deeply integrated into urban and semi-urban communication patterns.
This behaviour introduces significant challenges for ASR models, including:
- Script diversity: Devanagari ↔ Latin
- Phonetic and phonological overlaps
- Accent variability across regions
- Inconsistent orthographic conventions
Despite these realities, there has been no standardised benchmark for evaluating ASR models on code-switched speech. To bridge this gap, we developed the CoSHE-Eval, a Hindi–English benchmark curated through a hybrid pipeline combining multimodal transcription (Gemini 2.5 Pro - Thinking) and human verification for high-fidelity transcriptions.
Dataset Design Methodology
Overview
The dataset construction process followed a three-stage pipeline:
- Data Collection and Pre-processing
- Automated Transcription Generation
- Human Verification and Annotation
Each record in the ground-truth table contains:
| Column | Description |
|---|---|
audio_file_name | Unique identifier for each audio sample |
audio | Path or URI of the audio clip |
transcription | Final verified bilingual transcription including inline tags and metadata |
Data Collection and Pre-processing
Audio samples were curated from publicly available sources, spanning diverse speech contexts such as:
- Casual conversations, interviews, educational lectures, and podcasts
- Code-switching types: intra-sentential (within a sentence) and inter-sentential (between sentences)
Each clip was segmented into chunks of up to 59 seconds (median around 56s).
Note: No speaker demographic balancing (age, gender, accent) was performed intentionally, to preserve the natural variability of source material.
Automated Transcription Generation
Initial transcriptions were generated using Gemini 2.5 Pro (Thinking Mode) — a large multimodal reasoning model by Google DeepMind with advanced multilingual understanding. A custom system prompt was engineered to capture bilingual structure, tone, and contextual meaning.
Prompt Guidelines
The model was instructed to:
- Transcribe exactly as spoken — no translation or paraphrasing.
- Preserve natural code-mixing, using Devanagari for Hindi and Latin for English words.
- Convert English-origin words in Devanagari (e.g., “कंप्यूटर”) to “computer”.
- Retain word order, punctuation, and spacing faithfully.
- Handle multi-speaker dialogues without truncation.
- Insert inline emotion/tone tags (e.g.,
[calm],[sarcastically]).
This design enabled consistent multilingual fidelity while capturing the prosodic and emotional character of each utterance.
Human Verification and Annotation
Following automated transcription, each entry was subjected to manual review by human annotators to ensure precision and consistency.
Annotators verified:
- Word-level accuracy relative to the audio
- Script correctness (Devanagari vs. Latin)
- Emotion tag accuracy and placement
- Timestamp alignment
- Speaker continuity and code-switch boundary integrity
This human-in-the-loop process produces a high-confidence ground truth suitable for benchmarking fine-grained ASR performance.
Emotion and Tone Annotation
To capture paralinguistic nuances, Gemini was prompted to embed inline emotion and tone labels in square brackets.
| Category | Example Tags |
|---|---|
| Voice Delivery Styles | [excited], [whispering], [shouting], [rushed] |
| Emotional States | [nervous], [frustrated], [cheerfully], [calm] |
| Narrative / Structural Cues | [pause], [reflective], [dramatic tone] |
| Character Styles | [sarcastically], [matter-of-fact], [playfully] |
Although not used for the ASR benchmark itself, these enrichments make the dataset suitable for emotion-aware speech models and speech-to-text sentiment analysis.
Technical Specifications
| Attribute | Description |
|---|---|
| Total Samples | 1985 |
| Total Duration | ~30 hours |
| Minimum Segment Length | 0.60 seconds |
| Maximum Segment Length | 59.8 seconds |
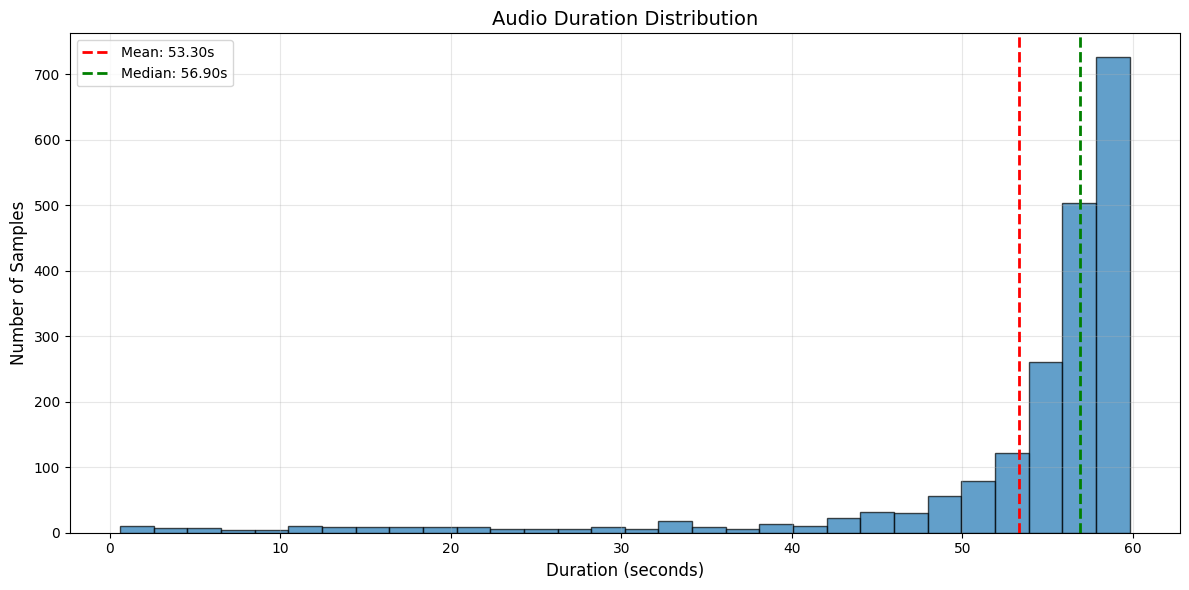
| Mean Segment Length | 53.3 seconds |
| Median Segment Length | 56.9 seconds |
| Timestamp Validation | Incremental and aligned with audio duration |
| Speaker Segmentation | Maintains full utterances; no mid-sentence cuts |
| Accent Labels | Haryanvi, UP Hindi, South Indian, Urban North Indian (where inferable) |
| Metadata Fields | speaker_id, gender, confidence_score, pitch, pace |
Duration Histogram
Intended Use and Limitations
- The dataset is intended solely for ASR evaluation and research purposes. It should not be used for commercial speech synthesis or training proprietary voice clones.
- Audio samples do not include heavily degraded or telephony-quality recordings.
- Speaker demographic metadata was not explicitly balanced. This preserves the organic diversity of open-domain Indian speech.
Conclusion and Future Work
The CoSHE-Eval fills a critical gap in ASR evaluation for bilingual Indian speech. By integrating multimodal transcription, emotion tagging, and human verification, it provides a high-quality benchmark for real-world code-switching performance assessment.
In upcoming releases, we plan to:
- Extend the dataset to other language pairs (e.g., Hindi–Marathi, Tamil–English).
- Include phoneme-level annotations and acoustic alignment.
Through these efforts, we aim to standardise evaluation of multilingual ASR models and foster open, reproducible research in Indian language technologies.
Legal Disclaimer
This dataset is distributed under a Research-Only, Non-Commercial License.
By accessing or using the dataset, you acknowledge and agree that:
- The dataset is provided “as-is” for academic research and evaluation purposes only.
- Use at your own understanding and risk — the authors and contributors assume no responsibility for any direct or indirect consequences arising from its use.
- Redistribution, commercial exploitation, or derivative datasets intended for commercial products are not permitted without explicit written consent from the maintainers.
- Users are expected to comply with all applicable copyright and data-protection regulations in their jurisdiction.